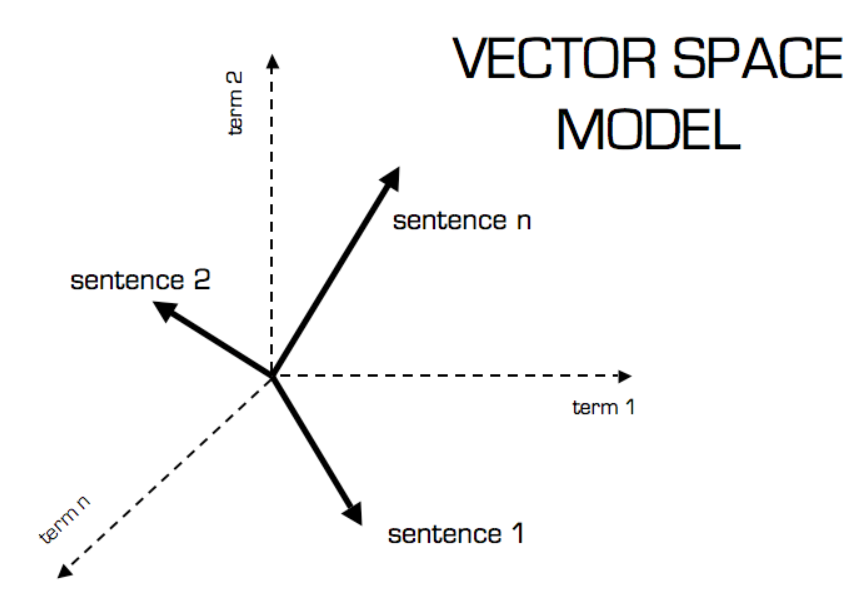
The Vector Space Model (VSM) is a technique used in information retrieval (IR) to analyze and compare text documents. It represents documents and queries as vectors in a high-dimensional space. Each dimension corresponds to a unique term in the entire collection of documents. The position of a vector in the space reflects the importance of each term to the document or query it represents.
The Vector Space Model (VSM) is a mathematical and algebraic model used in information retrieval to represent text documents (or any objects containing text) as vectors of identifiers. It is used primarily to determine the similarity between documents and a search query. Here’s a more detailed breakdown of its components and functionalities:
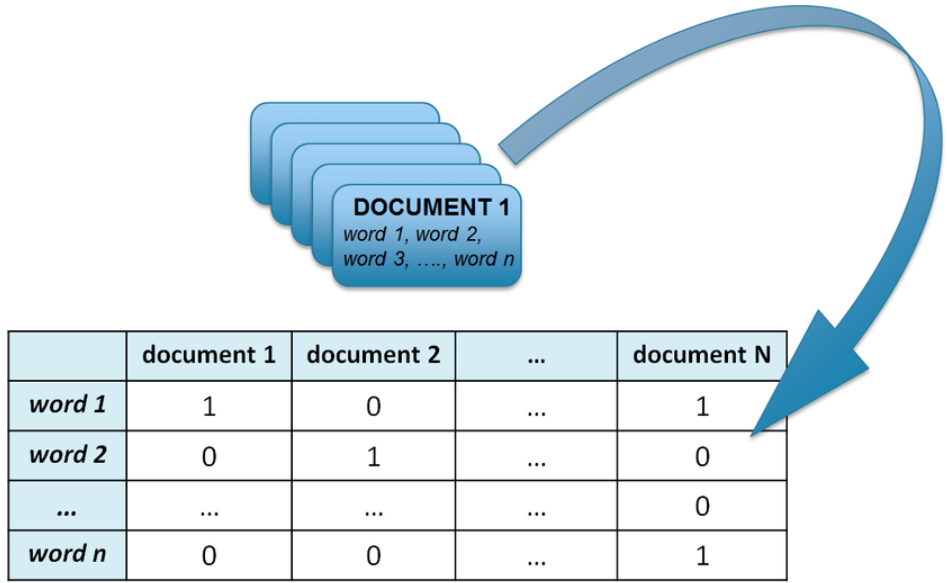
- Representation: In the VSM, each document is represented as a vector. Each dimension of the vector corresponds to a separate term from the document collection. If a term occurs in the document, its value in the vector is non-zero. These values are often weighted by the term’s importance in the document and across the document collection.
- Term Weighting: The most common scheme for determining the weights of the terms in the vectors is TF-IDF (Term Frequency-Inverse Document Frequency). TF measures the frequency of a term in a document, and IDF diminishes the weight of terms that occur very frequently across the document collection and increases the weight of terms that occur rarely.
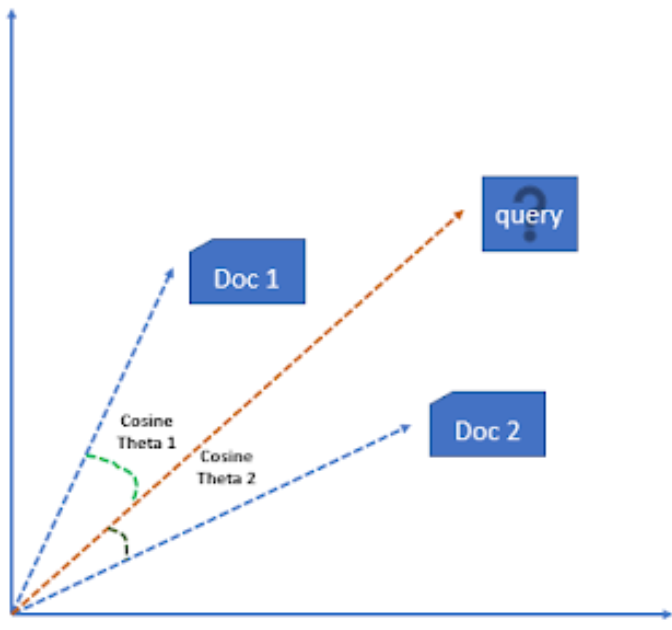
- Cosine Similarity: To find out how relevant a document is to a user’s query, cosine similarity is often used. This method calculates the cosine of the angle between the document vector and the query vector. Values closer to 1 represent a smaller angle and a greater similarity between the document and the query.
- Space Transformation: Sometimes, techniques such as Latent Semantic Indexing (LSI) are applied to reduce dimensions and capture the latent semantic relationships between words. This helps in dealing with synonyms and improving the accuracy of the retrieval.
The Vector Space Model is foundational in many modern search engines and systems handling textual data, enabling them to perform complex queries over large textual datasets efficiently.

Here’s a breakdown of the key aspects of VSM:
- Documents and queries as vectors: Documents and search queries are transformed into vectors, where each dimension represents a term.
- Term weights: The value at each dimension signifies the weight or significance of the corresponding term. This weight is determined by factors like term frequency (tf) and inverse document frequency (idf). Tf-idf basically tells you how important a term is to a specific document compared to the entire collection.
- Similarity between documents: Documents with similar terms and weights will be closer together in the vector space. This makes it possible to rank documents based on their relevance to a particular query. Cosine similarity is a common metric used to calculate the similarity between two vectors.
VSM is a foundational concept in information retrieval and is applied in various tasks like:
- Search engines: Ranking web pages based on their relevance to a search query.
- Document clustering: Grouping documents with similar content together.
- Recommendation systems: Recommending similar items (like products or articles) to a user based on their past preferences.