General Solr Terminology:
- Core: A core is a fundamental unit in Solr that represents a single logical index. It holds the schema (field definitions), configuration, and the actual indexed data. You can have multiple cores running on a single Solr instance.
- Schema: The schema defines the structure of your data within a core. It specifies the fields you want to index, their data types (text, integers, etc.), and any special handling they require.
- Document: An individual piece of data you want to store and search within Solr. It consists of various fields with corresponding values.
- Commit: The process of making changes to the index permanent. After a commit, new data becomes searchable.
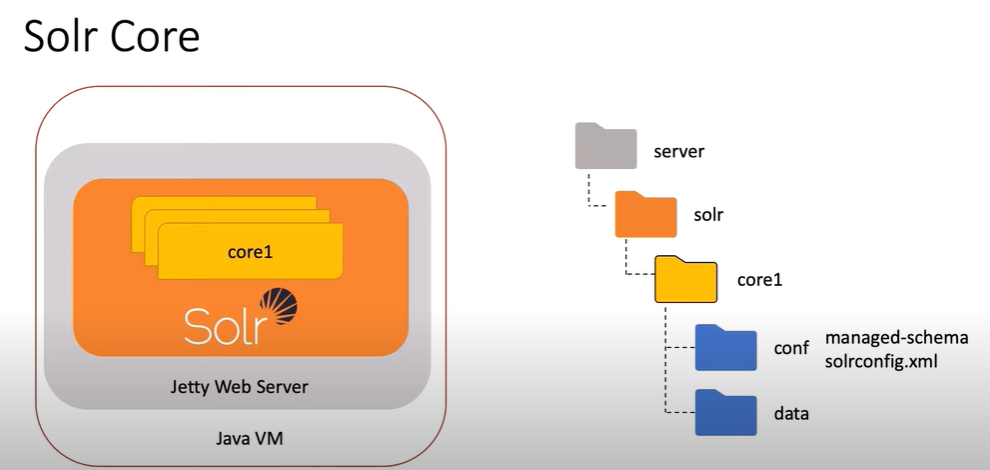
- $SOLR_HOME: This environment variable points to the directory containing all Solr cores, their configurations, schema, and dependencies.
- Document: The basic unit of information in Solr, which is indexed and searched. A document is a collection of fields.
- Field: A piece of information in a document. Each field has a defined data type and can be configured to have various properties in terms of indexing and searchability.
- Schema: Defines the fields and field types for documents in an index. The schema specifies the fields that can exist in a document and how those fields should be processed and queried.
- Index: The physical representation of a Solr data structure built using the Apache Lucene library. The index stores searchable tokens generated from the data sent to Solr.
- Tokenization: The process of breaking text down into smaller parts, called tokens, which are then indexed. This is part of the text analysis process.
- Analyzer: A component used during indexing and querying that applies a series of tokenizers and filters to transform field data into a format that enhances search effectiveness.
- Filter: In the context of an analyzer, a filter modifies the tokens generated by a tokenizer. Examples include lowercase filters, stop word filters, and synonym filters.
- Query Parser: Interprets the query string from the user and transforms it into a form that Solr can understand. Solr supports several query parsers, each designed for different types of search needs.
- Faceting: A feature that allows users to explore data by aggregating and counting occurrences of each unique value of a field.
- Boosting: A technique to increase or decrease the relevance of certain documents based on specific criteria during search queries.
SolrCloud Terminology (for distributed deployments):
- Node: An individual Solr server instance participating in a SolrCloud cluster.
- Cluster: A group of Solr nodes working together to manage a distributed index. They coordinate through a central service like Zookeeper.
- Collection: A logical view of an index in SolrCloud. It can be further divided into shards for scalability.
- Shard: A horizontal partition of a collection spread across multiple Solr nodes. Each shard holds a subset of the entire data.
- Replica: A copy of a shard running on a different Solr node within the cluster. This ensures redundancy and fault tolerance.
- Leader: A designated replica responsible for handling read/write requests for a particular shard and coordinating with other replicas.
- Zookeeper: An external service used by SolrCloud for centralized configuration management, cluster coordination, and leader election.
- Solr Instance (Solr Server): A running instance of Solr. This can refer to a single Solr server or a node in a SolrCloud cluster.
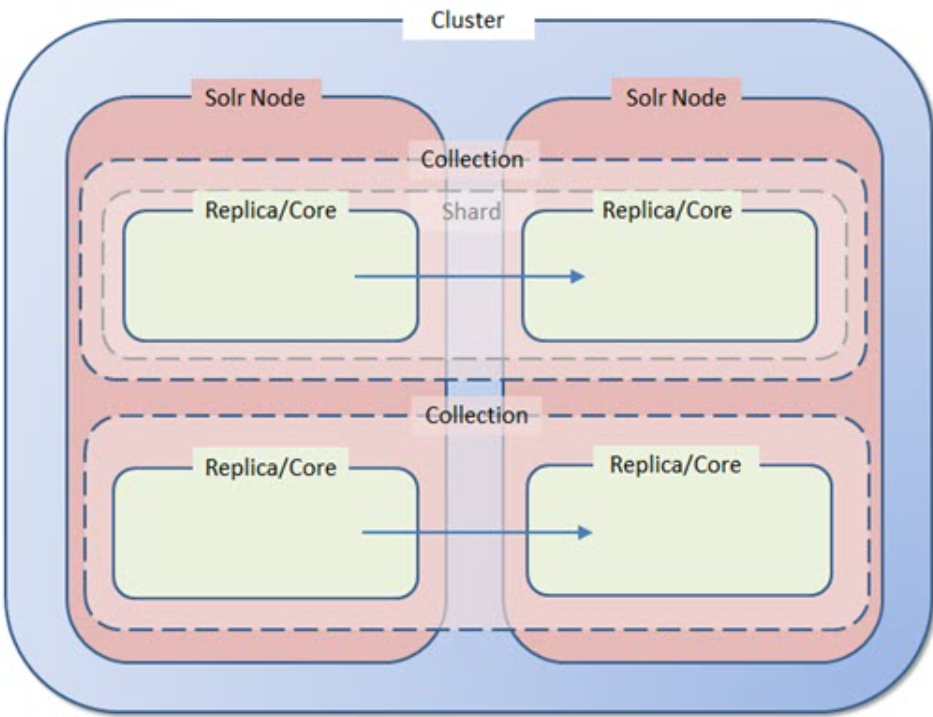
In Solr terminology, there is a sharp distinction between the logical parts of an index (collections, shards) and the physical manifestations of those parts (cores, replicas). In this diagram, the “logical” concepts are dashed/transparent, while the “physical” items are solid.
| Element | Description |
| Node | • one Solr node corresponds to one physical server. • Single-node systems are for testing and development. They do not provide the high-availability/fault-tolerant (HA/FT) behavior needed by production systems. • A single-node deployment uses an Nginx load-balancer. The log files are not available to the user. • The node hosts a single Zookeeper instance on the same server as Solr. • If Solr stops, query service stops. • A single-node system can be upgraded to increase memory, CPUs, and disk space. It cannot be expanded to create a cluster. |
| Cluster | • cluster has at least two Solr nodes to provide high-availability/fault-tolerant behavior. If a Solr issue degrades or stops one node, query traffic automatically continues on the other node(s). • A cluster has a dedicated Load Balancer. It stores a week of log files. • The cluster includes a three-node Zookeeper ensemble. The Zookeeper and Solr instances are not co-resident on the same servers. • There is no upper limit on the number of Solr nodes in a cluster. |
| Zookeeper Ensemble | • Zookeeper ensures that changes to config files and updates to index segments are automatically distributed across the nodes of the cluster. • It also determines which Solr server is the “leader” node for each of the collections. |
| Collection | • A “collection” is a single logical index in its entirety, regardless of how many replicas or shards it has. • One Solr node can host multiple collections. (A single Sitecore site typically generates over a dozen Solr collections.) |
| Shard | • A “shard” is a logical subset of the documents in a collection. Shards let us split a massive index across multiple servers. • SearchStax clients don’t usually subdivide their collections, so for our purposes a “shard” and a “collection” are the same thing. We rarely speak of shards. • Sharding multiplies the number of servers required to achieve high-availability/fault-tolerant behavior. • Sharding greatly complicates backup and restore operations. • If your index can fit comfortably on one server, then use one shard. This is Solr’s default behavior. |
| Core and Replica | • A “core” is a complete physical index on a Solr node. a “core” is replicated to multiple nodes. Therefore, “replicas” are cores. • Due to the details of index segment processing, replicas of an index are not all the same physical size. • To achieve high-availability/fault-tolerant (HA/FT) behavior, every node of the cluster must have a replica of every collection. • When you create a collection, set replicationFactor equal to the number of nodes in the cluster. Replication is automatic after that step. • It is a SearchStax convention to speak of replicas rather than cores, hopefully avoiding confusion. |
| High-Availability | • “High-availability (HA)” refers to a cluster of redundant Solr nodes, all of which can respond to queries. If one node goes down, the other nodes can temporarily take up the query load. |
| Fault-Tolerant | • “Fault-tolerance (FT)” enables Solr to continue to serve queries, possibly at a reduced level, rather than failing completely when a component of Solr gets into difficulty. • Solr/Zookeeper has fault-tolerant strategies such as automatically rebuilding a replica that has become unresponsive. These features handle mild issues if given enough time, but can become overwhelmed. |
| Rolling Restart | • When a Solr system has been severely stressed, its fault-tolerant features can get stuck in a degraded state. There are many possible ways for this to happen, frustrating a direct link from cause to result. • The “root cause” of this situation is usually that the client sent too many /update requests in too short a time, or that the updates were inefficient. CPU and memory became overloaded, and unneeded subsystems were shut down (but were not automatically restarted). • A “rolling restart” shuts down each Solr node in the cluster and restarts it. This returns Solr to a known state. Due to the cluster’s High Availability, this does not interrupt query service. • SearchStax provides a button on the Deployment Details screen to let you do a rolling restart at any time. |
| Disaster Recovery | • Disaster Recovery refers to:◦ A full duplicate production deployment (“Hot” DR) that can take over the query load at a moment’s notice.◦ A reduced-size production deployment than can be rapidly expanded (“Warm” DR).◦ Or a remotely-stored recent backup (“Cold” DR).• DR failover occurs automatically when High-Availability fails (all nodes have been unresponsive for five minutes ). |
Documents
Solr Core (similar to index)
A Solr Core is essentially a single index managed by Solr. It includes the configuration files necessary for Solr to understand how to index and search the data, the data itself, and the Solr software that processes requests and manages the index. A core is a fundamental unit of Solr capable of handling search requests independently.
- Key Aspects:
- Contains its own set of configuration files, such as
solrconfig.xmlandschema.xml. - Manages a single index.
- Operates independently but can exist alongside other cores within a single Solr instance (server).
- Contains its own set of configuration files, such as
Solr Collection (similar to index)
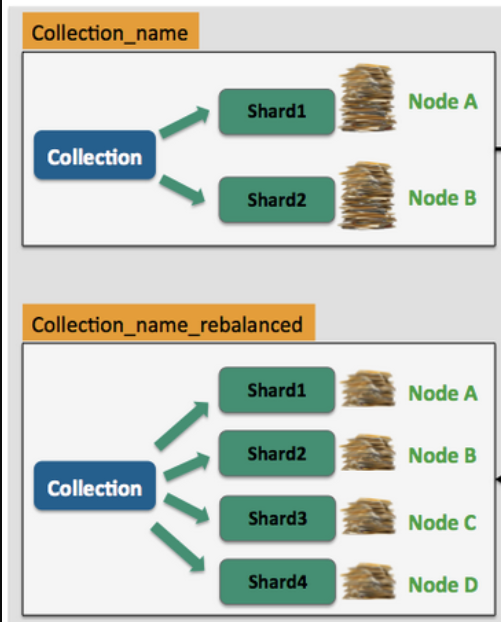
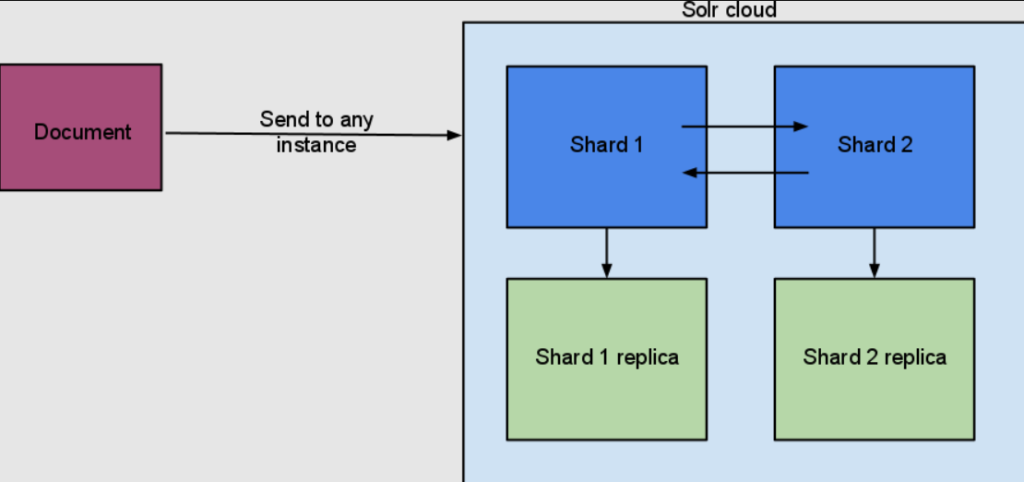
When Solr operates in a distributed mode (using SolrCloud), the concept of a Collection becomes relevant. A collection is a logical index that spans multiple Solr instances (Solr servers). Collections are split into multiple shards, with each shard hosting a subset of the collection’s data.
- Key Aspects:
- A collection is equivalent to a complete index but distributed across multiple servers.
- Supports horizontal scaling because data can be divided into multiple shards.
- Useful for achieving high availability and balancing load across servers.
Solr Shard
A Shard is a subset of a collection’s data. It is a partition of the entire collection’s dataset, enabling the distribution of the collection across multiple nodes. Each shard is, in itself, a complete Solr index.
- Key Aspects:
- Holds a part of the collection’s data.
- Each shard can be hosted on a different Solr node.
- Shards are essential for scaling large datasets across multiple nodes.
Solr Replica
Within each shard of a collection, there can be multiple replicas. These replicas are copies of the shard that exist to provide redundancy, failover, load balancing, and improved query performance. Solr uses ZooKeeper to manage the state of replicas across the cluster, and to balance queries and updates across them.
- Key Aspects:
- Each replica holds a copy of a shard’s data.
- Helps in providing high availability and fault tolerance.
- Used for distributing query load and handling failover in case a server goes down.
In a SolrCloud environment, these concepts interlink to provide a robust, scalable search architecture:
- Core: A single Solr instance managing a single index.
- Collection: A distributed index across multiple Solr instances, logically viewed as a single index.
- Shard: A partition of a collection’s data, each shard being a full index.
- Replica: Copies of a shard’s data, providing redundancy and load balancing.
Difference between Solr Collection and Replica and Core and Shards
Here’s a tabular comparison of the key Solr concepts: Core, Collection, Shard, and Replica. This format should help clarify the distinctions and roles of each in the context of Solr and SolrCloud.
| Concept | Definition | Role | Use in Solr/SolrCloud |
|---|---|---|---|
| Core | A single Solr instance managing one index. Includes its own configuration and index files. | Manages a single, complete index. Can handle queries and indexing operations independently. | Used in both standalone Solr setups and within each node in SolrCloud as part of collections. |
| Collection | A logical index spread across multiple Solr nodes or instances in SolrCloud. It is split into multiple shards. | Represents a complete index distributed across multiple servers. Enables horizontal scaling and load balancing. | Specific to SolrCloud, facilitating scalability and fault tolerance across multiple nodes. |
| Shard | A partition of a collection’s data. Each shard is a subset that holds a portion of the collection’s data and is a complete index on its own. | Allows distribution of the collection’s data across multiple nodes. Each shard can be hosted on a different node. | Essential in SolrCloud for distributing large datasets and enhancing search performance and scalability. |
| Replica | Copies of a shard’s data located on different or the same Solr nodes. Each replica is a full index. | Provides redundancy for high availability and load balancing of queries and updates. | Used in SolrCloud to ensure data availability and to improve query response times by distributing the load. |