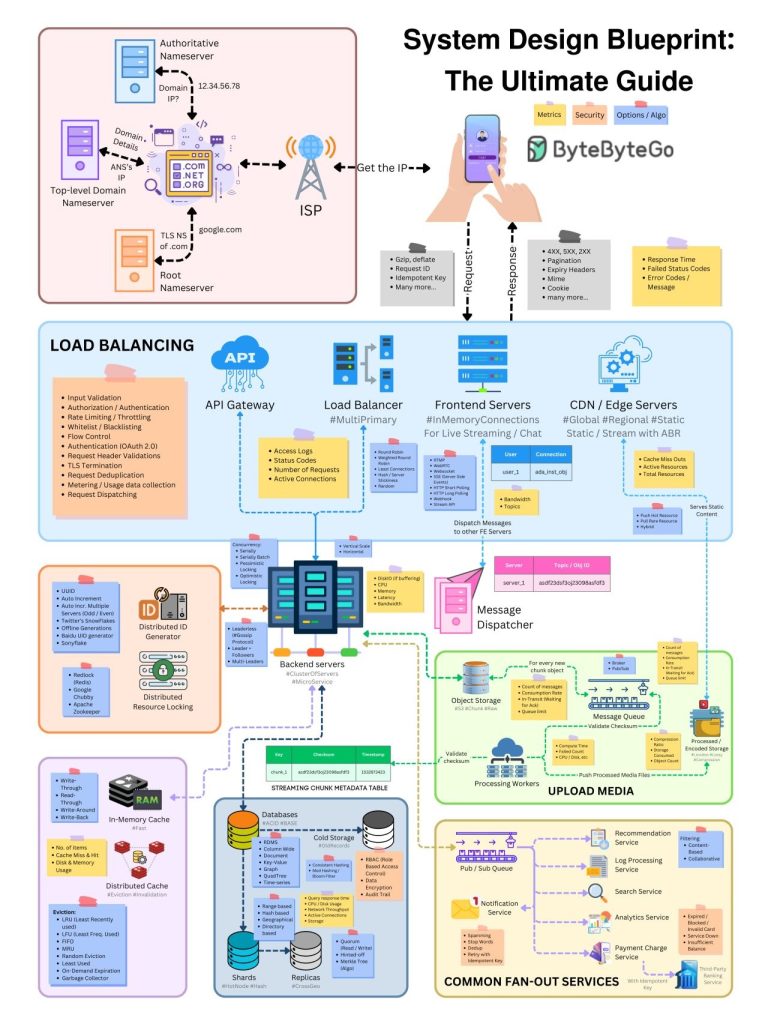
Here’s a comprehensive tutorial on System Design Blueprint: The Ultimate Guide, covering all fundamental concepts, principles, and best practices.
System Design Blueprint: The Ultimate Guide
Introduction
System design is the process of defining the architecture, components, modules, and interfaces for a system to meet specific requirements. It involves understanding scalability, performance, security, and maintainability.
This guide will cover:
- Basics of system design
- Architectural patterns
- Scaling strategies
- Data consistency models
- Best practices for designing robust, scalable systems
1. Fundamentals of System Design
Before diving into complex architectures, it’s essential to understand the key components:
1.1 Key Concepts
- Latency vs. Throughput – Lower latency means faster response time; higher throughput means handling more requests.
- CAP Theorem – A distributed system can only guarantee two out of three: Consistency, Availability, and Partition Tolerance.
- ACID vs. BASE – ACID ensures strong consistency, while BASE prioritizes scalability with eventual consistency.
1.2 Common Components in System Design
- Load Balancer – Distributes incoming traffic across multiple servers.
- Caching – Reduces latency by storing frequently accessed data.
- Message Queues – Enables asynchronous processing for better scalability.
- Database – Can be SQL (MySQL, PostgreSQL) or NoSQL (MongoDB, Cassandra).
- CDN (Content Delivery Network) – Delivers static content faster from edge locations.
- API Gateway – Manages API requests, authentication, and routing.
2. High-Level System Design Process
A structured approach to designing scalable systems:
2.1 Requirements Gathering
- Functional Requirements – What the system should do.
- Non-Functional Requirements – Performance, security, reliability.
- Constraints – Hardware, budget, regulatory compliance.
2.2 Define the High-Level Architecture
- Identify components (frontend, backend, databases, caching).
- Decide on monolithic vs. microservices architecture.
- Consider synchronous vs. asynchronous communication.
2.3 Scaling Strategies
- Vertical Scaling – Adding more resources (CPU, RAM) to a single machine.
- Horizontal Scaling – Adding more machines (distributed systems).
- Load Balancing – Evenly distributing traffic among servers.
3. Architectural Patterns
Different design patterns help build scalable and maintainable systems.
3.1 Monolithic Architecture
- Single-codebase with tightly coupled components.
- Easy to develop and deploy but hard to scale.
3.2 Microservices Architecture
- Breaks the system into loosely coupled, independently deployable services.
- Enables better scalability and fault isolation.
3.3 Event-Driven Architecture
- Uses messaging queues (Kafka, RabbitMQ) for decoupled communication.
- Ideal for real-time applications like stock trading or ride-sharing apps.
3.4 Serverless Architecture
- Deploy code without managing servers (AWS Lambda, Azure Functions).
- Best for lightweight, event-driven workloads.
4. Database Design in System Architecture
Choosing the right database depends on system requirements.
4.1 SQL vs. NoSQL
| Feature | SQL (MySQL, PostgreSQL) | NoSQL (MongoDB, Cassandra) |
|---|---|---|
| Structure | Structured Tables | Key-Value, Document, Graph |
| Transactions | ACID-compliant | BASE (Eventual Consistency) |
| Scaling | Vertical Scaling | Horizontal Scaling |
| Use Case | Banking, E-commerce | Big Data, Social Media |
4.2 Sharding & Replication
- Sharding – Distributing data across multiple nodes to improve performance.
- Replication – Keeping multiple copies of data for redundancy.
5. Caching Strategies
Caching reduces database load and improves response time.
5.1 Types of Caching
- Application Caching – Local memory (e.g., Redis, Memcached).
- Database Caching – Indexing, query optimization.
- CDN Caching – Caching static assets on edge servers.
5.2 Cache Invalidation Strategies
- Write-through – Updates cache and database simultaneously.
- Write-back – Updates cache first, then the database.
- Write-around – Writes directly to the database, skipping the cache.
6. API Design Principles
APIs enable communication between different system components.
6.1 REST vs. GraphQL
| Feature | REST | GraphQL |
|---|---|---|
| Data Fetching | Multiple endpoints | Single endpoint |
| Performance | Over-fetching possible | Only requested data returned |
| Use Case | Simple APIs | Complex queries & real-time apps |
6.2 Rate Limiting
- Prevents abuse and protects system resources.
- Implemented using token bucket, leaky bucket, sliding window algorithms.
7. Security Considerations
A well-designed system must be secure.
7.1 Authentication & Authorization
- OAuth 2.0 – Token-based authentication.
- JWT (JSON Web Token) – Stateless authentication.
- RBAC (Role-Based Access Control) – Defines access permissions.
7.2 Data Encryption
- In-transit encryption (TLS, HTTPS).
- At-rest encryption (AES, Hashing).
7.3 DDoS Protection
- Rate limiting and firewalls to prevent attacks.
- WAF (Web Application Firewall) to filter malicious traffic.
8. Monitoring and Logging
Observability ensures system reliability.
8.1 Monitoring Tools
- Prometheus – Metrics collection.
- Grafana – Data visualization.
- New Relic / Datadog – Full-stack monitoring.
8.2 Logging Best Practices
- Centralized logging with ELK Stack (Elasticsearch, Logstash, Kibana).
- Use structured logging for better analysis.
9. Case Study: Designing a Scalable URL Shortener
9.1 Requirements
- Shorten long URLs and provide redirection.
- Handle 100M requests/day.
9.2 High-Level Design
- Load Balancer – Distributes requests.
- Application Servers – Processes requests.
- Database (NoSQL – Redis) – Stores URL mappings.
- CDN – Caches frequent requests.
- Hashing Function – Converts URLs into unique keys.
9.3 Scaling
- Database Partitioning – Distribute URLs across multiple servers.
- Caching – Use Redis for faster lookups.
- Asynchronous Processing – Log analytics data in background jobs.
10. System Design Interview Tips
- Clarify requirements before designing.
- Break down the system into components.
- Discuss trade-offs between different approaches.
- Sketch a diagram to visualize the architecture.
10.1 Example System Design Questions
- Design YouTube
- Design WhatsApp
- Design an E-commerce System
- Design Google Docs
Case Study: Designing a Scalable Ride-Sharing System (Uber/Lyft) 🚖
1. Introduction
Ride-sharing platforms like Uber and Lyft connect passengers with drivers in real-time, handling millions of concurrent users globally. Designing such a system requires considerations for high availability, low latency, real-time tracking, and scalability.
2. Requirements Gathering
Before designing, we break down the system into:
2.1 Functional Requirements
✅ Allow passengers to request a ride.
✅ Match passengers with nearby drivers.
✅ Track drivers and passengers in real time.
✅ Support payments and ride history.
✅ Provide estimated fare and arrival time.
2.2 Non-Functional Requirements
⚡ Low Latency – Instant ride-matching.
⚡ Scalability – Handle millions of concurrent users.
⚡ Fault Tolerance – No downtime.
⚡ Security – Secure transactions and user authentication.
2.3 Constraints
- Response Time: <1 second for ride-matching.
- User Base: Millions of concurrent users.
- Data Storage: Location updates every 5 seconds.
3. High-Level System Design
3.1 Architecture Overview
The system consists of:
- API Gateway (Entry point for all requests).
- Load Balancer (Distributes traffic).
- Microservices:
- Passenger Service (Handles ride requests).
- Driver Service (Handles driver availability).
- Matching Service (Matches drivers to passengers).
- Ride Management Service (Tracks rides, fares, etc.).
- Real-Time Location Tracking (Uses WebSockets & Kafka).
- Data Storage:
- Relational DB (User details, payments).
- NoSQL DB (Ride history, location data).
- Caching Layer (Redis for frequent lookups).
4. Key Components
4.1 Ride Matching Algorithm
- Nearest Driver First: Selects drivers based on distance.
- Load Balancing: If all nearby drivers are busy, expand the search radius.
- Surge Pricing: Increases fares when demand is high.
Implementation:
- Get passenger’s location from the request.
- Query the real-time driver location cache (Redis).
- Apply Haversine Formula to compute distance.
- Select the nearest available driver.
🔹 Tech Stack: Redis + Geospatial Queries + Kafka.
4.2 Real-Time Location Tracking
- WebSockets for real-time updates.
- Kafka for event streaming (driver locations).
- Redis for storing the latest locations.
🔹 How it Works:
- Drivers send GPS updates every 5 seconds.
- Updates are streamed via Kafka.
- Redis stores the latest driver coordinates.
- Passenger apps receive live updates via WebSockets.
4.3 Payment & Fare Calculation
- Payment Gateway (Stripe, PayPal, Razorpay).
- Fare Calculation:
- Base Fare + Distance Fare + Surge Pricing.
- Uses Google Maps API for distance estimation.
🔹 Tech Stack: PostgreSQL for transactions, Redis for caching fare calculations.
4.4 Database Schema
Users Table
| Field | Type | Description |
|---|---|---|
| user_id | UUID | Unique user ID |
| name | String | User’s name |
| phone | String | Contact number |
| type | Enum | Passenger / Driver |
| location | GeoJSON | Current GPS coordinates |
Rides Table
| Field | Type | Description |
|---|---|---|
| ride_id | UUID | Unique Ride ID |
| passenger_id | UUID | User requesting the ride |
| driver_id | UUID | Assigned driver ID |
| status | Enum | Requested, Ongoing, Completed |
| fare | Float | Total ride cost |
5. Scalability & Performance Optimization
5.1 Load Balancing
- API Gateway + Nginx Load Balancer to handle millions of requests.
- Round-robin & Weighted Load Balancing for distributing traffic.
5.2 Caching Strategies
- Redis for hot data (e.g., driver locations, ride status).
- CDN for static content (e.g., images, maps).
5.3 Sharding & Replication
- Geo-based Sharding: Users in different cities store data in different database clusters.
- Read Replicas: PostgreSQL replicas for handling high read traffic.
6. Security Measures
🔒 Authentication – OAuth 2.0, JWT tokens.
🔒 Data Encryption – AES for at-rest, TLS for in-transit data.
🔒 Fraud Detection – Machine Learning to detect fake rides.
7. Monitoring & Logging
📊 Prometheus + Grafana for real-time monitoring.
📊 Elasticsearch + Kibana (ELK Stack) for logs.
📊 Sentry for error tracking.
8. Tech Stack
| Component | Technology |
|---|---|
| Backend API | Node.js / Go / Python |
| Database | PostgreSQL + MongoDB |
| Caching | Redis / Memcached |
| Load Balancing | NGINX / AWS ALB |
| Real-Time Tracking | Kafka + WebSockets |
| Payments | Stripe / Razorpay |
| Monitoring | Prometheus + Grafana |
9. Future Enhancements
🚀 AI-based Driver Matching – Predicting ETAs using ML.
🚀 Dynamic Pricing Optimization – AI-driven surge pricing.
🚀 Blockchain-based Ride History – Immutable ride records.
Conclusion
This case study breaks down the system design of Uber/Lyft into functional, architectural, and scalability considerations. By leveraging caching, real-time updates, distributed storage, and security measures, we can design an efficient ride-sharing platform.