What is MongoDB?
MongoDB is a popular NoSQL database known for its flexibility and scalability. Here are some key points about MongoDB:
Overview:
- Type: NoSQL database
- Data Model: Document-oriented, meaning data is stored in JSON-like documents.
- Schema: Schema-less or flexible schema, allowing for dynamic changes in the structure of documents.
- Language: Query language similar to SQL, known as MongoDB Query Language (MQL).
Key Features:
- Document Storage: Stores data in flexible, JSON-like documents which can have varied structures.
- Scalability: Designed to scale out by distributing data across multiple servers, making it suitable for large-scale applications.
- High Performance: Optimized for read and write operations, providing high performance and efficiency.
- Replication: Supports replica sets for high availability and data redundancy.
- Sharding: Enables horizontal scaling by partitioning data across multiple servers.
- Indexing: Supports various types of indexing to improve query performance.
Use Cases:
- Big Data: Handles large volumes of data efficiently.
- Real-time Analytics: Suitable for applications requiring real-time data processing and analysis.
- Content Management: Flexible schema makes it ideal for managing dynamic content.
- Internet of Things (IoT): Efficiently handles the vast amount of data generated by IoT devices.
- Mobile Applications: Supports offline data storage and synchronization.
Advantages:
- Flexibility: No predefined schema allows for rapid iteration and development.
- Performance: Optimized for fast read and write operations.
- Scalability: Easy to scale horizontally, making it suitable for growing applications.
Disadvantages:
- Complex Transactions: Not as strong in handling complex multi-document transactions as traditional relational databases.
- Memory Usage: Can be more memory-intensive compared to relational databases.
Example Use:
MongoDB is often used in modern web applications, such as content management systems (CMS), social networks, and real-time analytics platforms. It is favored for applications that require a flexible, schema-less data model and need to handle large volumes of unstructured data.
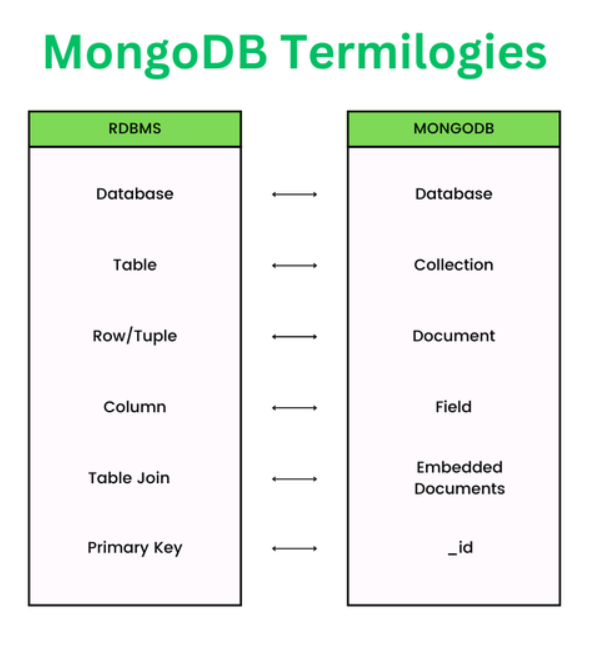
Terminology used in MongoDB
| Term | Description |
|---|---|
| Document | The basic unit of data in MongoDB, stored in BSON format (Binary JSON). |
| Collection | A group of MongoDB documents, similar to a table in relational databases. |
| Database | A logical container for collections in MongoDB. |
| BSON | Binary-encoded serialization of JSON-like documents, used internally by MongoDB. |
| Replica Set | A group of MongoDB servers that maintain the same data set, ensuring high availability. |
| Sharding | The process of distributing data across multiple machines to support horizontal scaling. |
| Shard | An individual partition of data in a sharded cluster, can be a single server or a replica set. |
| Mongos | The query router for a sharded cluster, directing operations to the appropriate shard. |
| Primary Node | In a replica set, the node that receives all write operations. |
| Secondary Node | Nodes in a replica set that replicate data from the primary and can be promoted if the primary fails. |
| Index | Data structure that improves the speed of data retrieval operations on a collection. |
| Aggregation | A framework for performing operations like filtering, grouping, and sorting on documents. |
| Pipeline | A series of aggregation stages that process documents in sequence. |
| GridFS | A specification for storing and retrieving large files by dividing them into smaller chunks. |
| Query | An operation to retrieve data from a collection based on specified criteria. |
| Schema | The structure of documents in a collection, though MongoDB supports flexible schema designs. |
| ACID | Atomicity, Consistency, Isolation, Durability – properties ensuring reliable database transactions. |
| CRUD | Create, Read, Update, Delete – the basic operations performed on database data. |
| Write Concern | The level of acknowledgment requested from MongoDB for write operations. |
| Read Preference | The preferred replica set member to use for read operations. |
| TTL Index | A special type of index that removes documents after a certain period. |
| Change Streams | A feature that allows applications to access real-time data changes without polling the database. |
| Replica | A duplicate of the data set, used in replication for high availability. |
| MQL | MongoDB Query Language, used to query documents in MongoDB collections. |
MongoDB Architecture
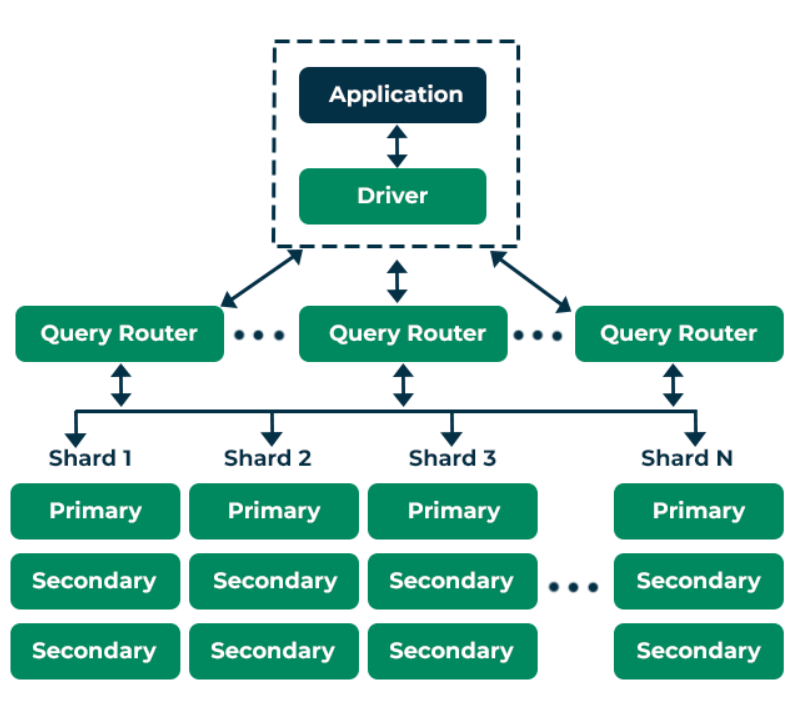
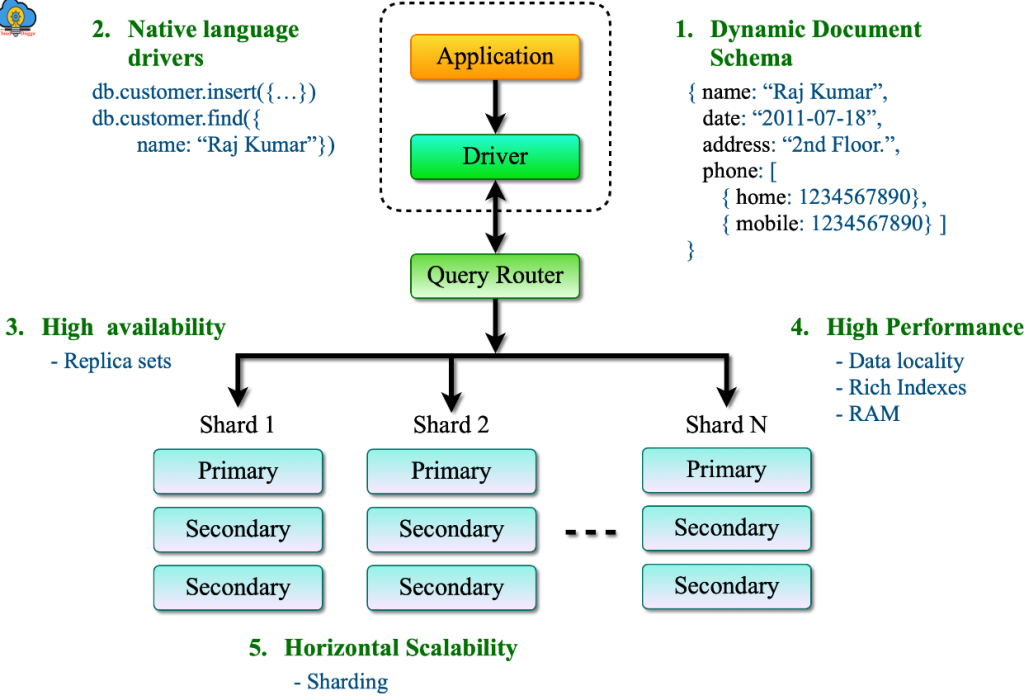
MongoDB’s architecture is designed to provide high availability, scalability, and performance. Here are the key components and concepts of MongoDB architecture:
1. Document-Based Storage
- Documents: MongoDB stores data in BSON (Binary JSON) format. Each document contains key-value pairs, similar to JSON objects.
- Collections: Documents are grouped into collections, which are analogous to tables in relational databases. A collection can hold multiple documents, and documents within a collection can have different structures.
2. Replica Sets
- Replication: MongoDB ensures high availability through replica sets. A replica set is a group of MongoDB instances that maintain the same data set.
- Primary and Secondary Nodes: In a replica set, one node is the primary node that handles all write operations. The secondary nodes replicate the data from the primary node and can be promoted to primary if the current primary fails.
- Automatic Failover: If the primary node goes down, an election process occurs among the secondary nodes to select a new primary, ensuring minimal downtime.
3. Sharding
- Horizontal Scaling: MongoDB uses sharding to distribute data across multiple servers, allowing for horizontal scaling.
- Shards: Each shard is a subset of the data and can be a single MongoDB instance or a replica set.
- Shard Key: A shard key is a field that determines how data is distributed across shards. The choice of shard key impacts the performance and scalability of the database.
- Mongos: The query router that directs client requests to the appropriate shard based on the shard key. Mongos instances handle query routing and provide a unified interface to the client.
4. Indexing
- Indexes: MongoDB supports various types of indexes, including single field, compound, multi-key, geospatial, and text indexes. Indexes improve the efficiency of query operations by allowing faster data retrieval.
- Index Creation: Indexes can be created on fields within documents to optimize read performance.
5. Aggregation Framework
- Data Processing: The aggregation framework allows for complex data processing and transformation operations. It includes operations like filtering, grouping, and sorting.
- Pipeline Stages: Aggregation pipelines consist of multiple stages, each performing a specific operation on the data. Examples include
$match,$group,$sort,$project, and$lookup.
6. GridFS
- File Storage: GridFS is a specification for storing and retrieving large files, such as images, videos, and documents, within MongoDB.
- File Chunks: Files are divided into smaller chunks and stored as separate documents. GridFS provides a way to query and retrieve these files.
7. Security
- Authentication: MongoDB supports various authentication mechanisms, including username/password, LDAP, Kerberos, and x.509 certificates.
- Authorization: Role-based access control (RBAC) allows administrators to define roles and permissions for different users and applications.
- Encryption: Data can be encrypted both at rest and in transit to ensure data security.
How MongoDB Store Data?
MongoDB stores data in a flexible, document-oriented format, allowing for a more dynamic and scalable approach compared to traditional relational databases. Here’s an overview of how MongoDB stores data:
1. Documents
- Format: MongoDB stores data in BSON (Binary JSON) format, which is a binary representation of JSON-like documents. BSON supports more data types than JSON, including dates and binary data.
- Structure: Each document is composed of field and value pairs. Fields are similar to columns in a relational database, and values can be a variety of data types, including other documents, arrays, and arrays of documents.
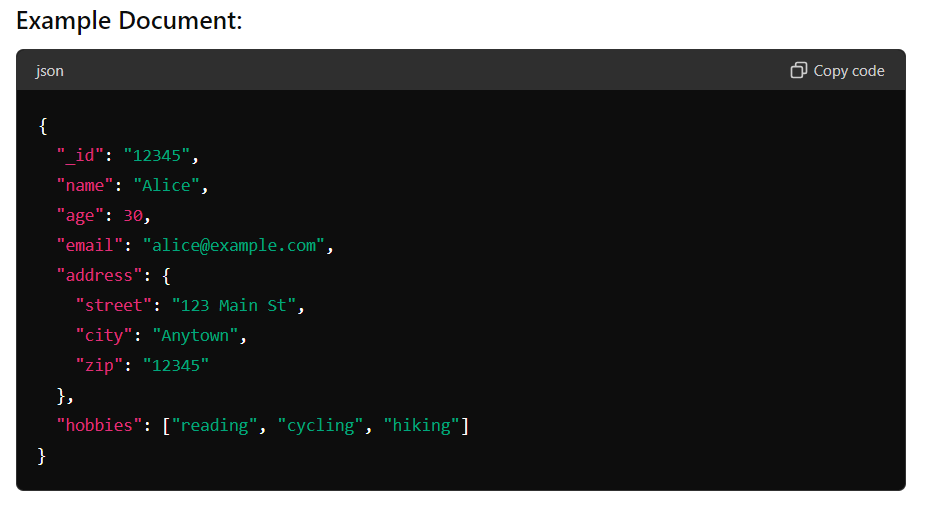
2. Collections
- Group of Documents: Documents are grouped into collections. A collection is analogous to a table in a relational database, but it does not enforce a schema, allowing documents within a collection to have different structures.
- Namespace: Collections are identified by a name within a database. Collections can be created implicitly by inserting a document.
3. Databases
- Logical Grouping: A database is a logical grouping of collections. Each database has its own set of files on the filesystem.
- Multiple Databases: MongoDB can host multiple databases on a single server instance, each independent of the others.
4. Storage Engine
- WiredTiger: The default storage engine in MongoDB is WiredTiger, which supports features like document-level locking, compression, and checkpointing.
- MMAPv1: An older storage engine, MMAPv1, is based on memory-mapped files but is less commonly used in newer MongoDB versions.
- Pluggable Storage Engines: MongoDB supports pluggable storage engines, allowing the use of different storage backends based on specific needs.
5. Indexing
- Performance Optimization: Indexes are used to improve the performance of read operations by allowing efficient data retrieval.
- Types of Indexes: MongoDB supports various types of indexes, including single field, compound, multi-key, geospatial, text, and hashed indexes.
- Creation and Management: Indexes can be created on any field or subfield within a document and are managed independently of the document structure.
6. Sharding
- Horizontal Scaling: MongoDB supports horizontal scaling through sharding, which involves partitioning data across multiple servers.
- Shard Key: A shard key is chosen to determine how data is distributed across shards. The choice of shard key impacts the performance and balance of the distributed data.
- Chunks: Data is divided into chunks based on the shard key, and these chunks are distributed across the shards.
7. Replication
- High Availability: MongoDB ensures high availability through replica sets. A replica set is a group of MongoDB instances that replicate data among them.
- Primary and Secondary Nodes: In a replica set, one node is the primary node that handles all write operations, while secondary nodes replicate the data and can serve read operations.
8. GridFS
- Large File Storage: GridFS is a specification for storing and retrieving large files by dividing them into smaller chunks.
- Chunks and Metadata: Files are divided into chunks and stored in two collections: one for the chunks and one for the file metadata.
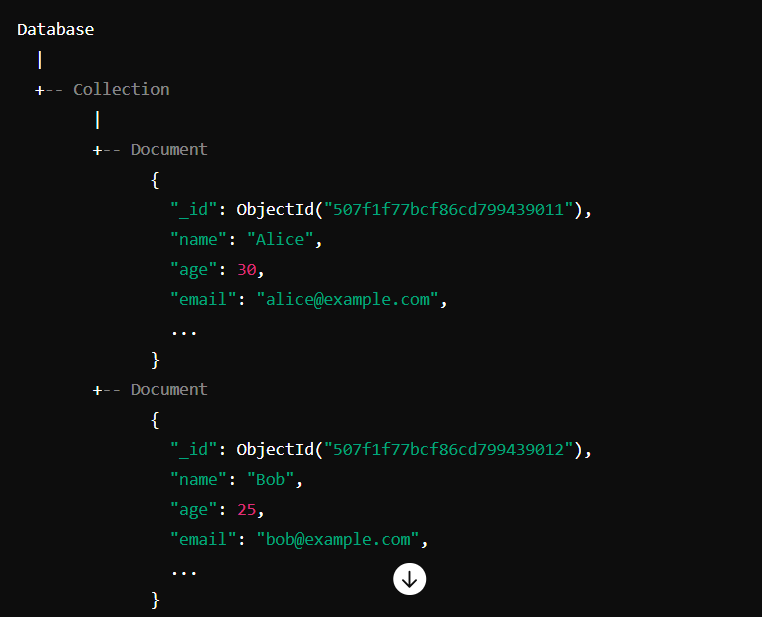
Storage Layout
Here’s a simplified visualization of MongoDB’s storage layout:
Difference Between SQL and NOSQL
SQL and NoSQL databases are designed to handle different types of data and workloads. Here are the key differences between them:
1. Data Model
SQL Databases:
- Structured Data: SQL databases use a structured data model, storing data in tables with predefined schemas.
- Schema: Schema defines the structure of data, including tables, columns, and data types. Schema changes are often rigid and require altering the database structure.
- Relationships: Strong support for relationships through foreign keys and JOIN operations.
NoSQL Databases:
- Unstructured or Semi-structured Data: NoSQL databases can handle unstructured or semi-structured data, including documents, key-value pairs, wide-column stores, and graphs.
- Flexible Schema: NoSQL databases have a flexible schema, allowing for dynamic and on-the-fly changes to data structures.
- Varied Data Models: Includes document stores (e.g., MongoDB), key-value stores (e.g., Redis), wide-column stores (e.g., Cassandra), and graph databases (e.g., Neo4j).
2. Scalability
SQL Databases:
- Vertical Scaling: Typically scale vertically by adding more resources (CPU, RAM, storage) to a single server.
- Limited Horizontal Scaling: Horizontal scaling (scaling out by adding more servers) is possible but more complex due to the relational model.
NoSQL Databases:
- Horizontal Scaling: Designed to scale out easily by adding more servers to the database cluster.
- Partitioning: Uses sharding or partitioning to distribute data across multiple nodes, making it more suitable for large-scale applications.
3. Query Language
SQL Databases:
- Structured Query Language (SQL): Use SQL for defining and manipulating data. SQL is a standard language with powerful query capabilities.
- ACID Transactions: Strong support for ACID (Atomicity, Consistency, Isolation, Durability) properties, ensuring reliable and consistent transactions.
NoSQL Databases:
- Varied Query Languages: Different NoSQL databases use different query languages or APIs specific to their data models (e.g., MongoDB Query Language, CQL for Cassandra).
- Eventual Consistency: Many NoSQL databases use eventual consistency models, providing high availability and partition tolerance but may not guarantee immediate consistency across all nodes.
4. Use Cases
SQL Databases:
- Structured Data Applications: Suitable for applications with structured data and complex queries, such as financial systems, enterprise resource planning (ERP), and customer relationship management (CRM).
- Transactions: Ideal for applications requiring complex transactions and strong consistency, such as banking and e-commerce systems.
NoSQL Databases:
- Unstructured Data Applications: Suitable for applications with large volumes of unstructured or semi-structured data, such as social media platforms, content management systems, and big data analytics.
- Real-time Applications: Ideal for applications requiring high throughput and low latency, such as IoT, real-time analytics, and gaming.
5. Examples
SQL Databases:
- MySQL: Open-source relational database management system.
- PostgreSQL: Advanced open-source relational database with support for additional data types.
- Oracle Database: Enterprise-grade relational database system.
- Microsoft SQL Server: Comprehensive relational database system from Microsoft.
NoSQL Databases:
- MongoDB: Document-oriented database storing data in JSON-like documents.
- Cassandra: Wide-column store designed for high availability and scalability.
- Redis: In-memory key-value store known for its performance.
- Neo4j: Graph database designed for storing and querying graph data.
6. Examples of Use Cases
SQL:
- Banking Systems: Where data integrity and complex transactions are crucial.
- Inventory Management: Structured data with defined relationships.
- Government Systems: Requires structured data and complex reporting.
NoSQL:
- Social Media Platforms: Handling large volumes of unstructured data.
- Real-time Analytics: Requires fast read and write operations.
- Content Management: Flexible data structures that can evolve over time.
Summary
| Feature | SQL Databases | NoSQL Databases |
|---|---|---|
| Data Model | Structured, table-based | Unstructured/Semi-structured, flexible |
| Schema | Fixed, predefined | Dynamic, flexible |
| Scalability | Vertical | Horizontal |
| Query Language | SQL | Varied (e.g., MQL, CQL) |
| Consistency | Strong ACID properties | Eventual consistency (in many cases) |
| Use Cases | Structured data, complex transactions | Large volumes of unstructured data, real-time applications |
| Examples | MySQL, PostgreSQL, Oracle, SQL Server | MongoDB, Cassandra, Redis, Neo4j |
Each type of database has its strengths and is suitable for different types of applications and data requirements.